World Model V-JEPA 2
V-JEPA 2 is Meta's clearest version of the JEPA bet: learn by predicting representations of the world, not by reconstructing pixels. Meta describes the model as a 1.2B-parameter video world model trained on more than one million hours of internet video, then adapted into an action-conditioned planner with less than 62 hours of robot video from DROID (Meta V-JEPA project page, Meta V-JEPA 2 blog, V-JEPA 2 paper, DROID paper). The mechanism matters because it separates understanding from rendering. A world model does not need to draw every leaf in a scene to predict that an object will keep moving behind it.
Latent Prediction
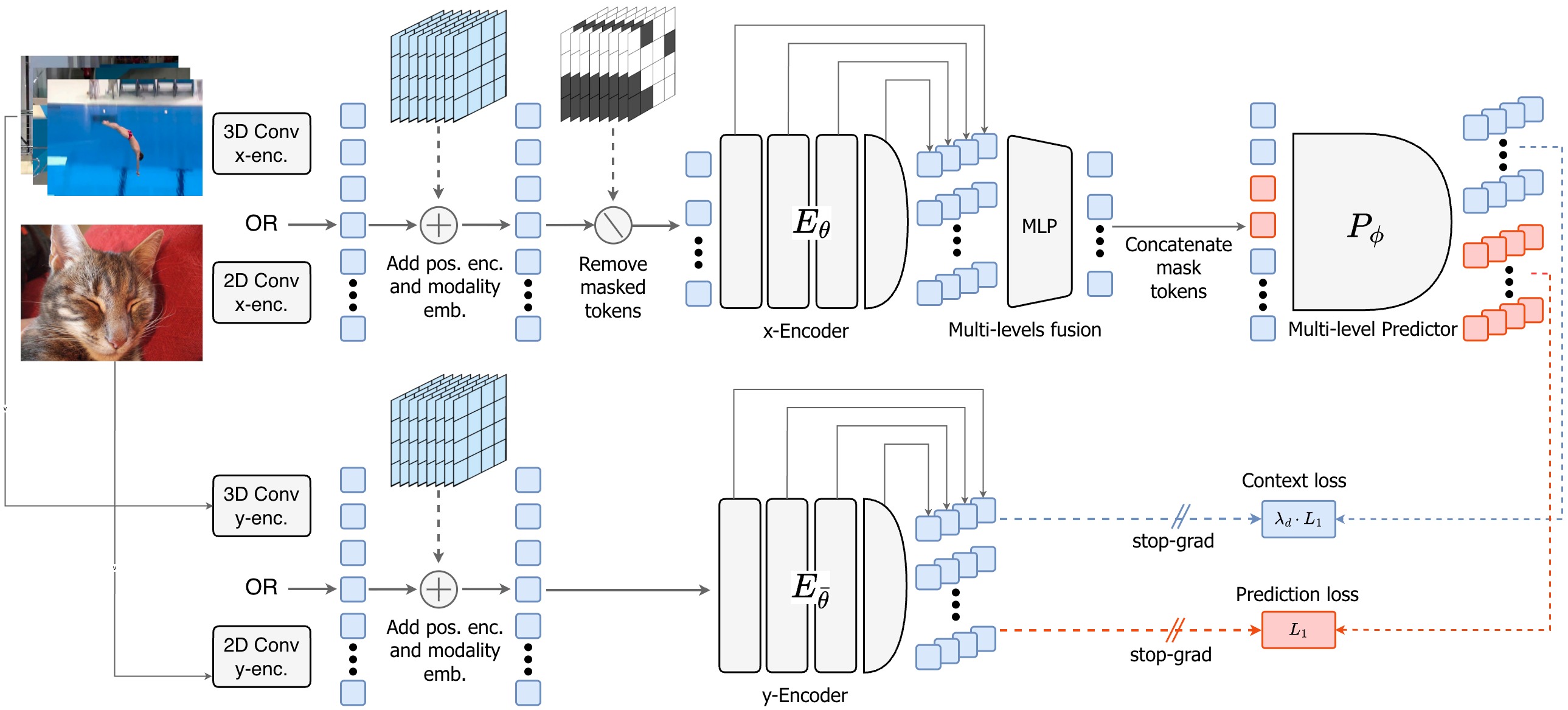
Joint-Embedding Predictive Architecture, or JEPA, predicts in representation space. A context encoder processes visible patches. A target encoder processes the target view. A predictor learns to map the context representation toward the target representation, so the loss compares embeddings rather than raw pixels (I-JEPA paper, V-JEPA 2 paper).
This design avoids forcing the model to spend capacity on photorealistic detail. Pixel reconstruction penalizes every texture mismatch. Latent prediction can focus on structure, object relations, and motion, because the target representation can discard visual noise that does not help the predictive task.
I-JEPA to Video
I-JEPA showed the idea on images by masking large regions and predicting their representations from visible context, without labels or pixel reconstruction (I-JEPA paper). V-JEPA extends the same family of ideas to video, where the model has to represent motion and temporal structure rather than only spatial context (V-JEPA 2 paper).
The move from image to video changes the value of the objective. In images, the model learns what parts of a scene imply other parts. In video, the model learns what the current state implies about the future. That is why JEPA becomes more interesting as a world-model architecture than as another self-supervised image pretraining method.
V-JEPA 2 Training
Meta frames V-JEPA 2 as a two-phase system. First, the model learns video representations from more than one million hours of unlabeled internet video. Second, the action-conditioned variant, V-JEPA 2-AC, learns to predict future latent observations given robot actions using less than 62 hours of DROID robot video (Meta V-JEPA project page, V-JEPA 2 paper, DROID paper).
That data split is the important part. Most of the physical prior comes from passive video. The robot data teaches the model how actions change observations. If that separation holds, world-model pretraining can become a reusable substrate for robotics instead of requiring every robot skill to learn physics from scratch.
Action-Conditioned Planning
V-JEPA 2-AC plans in latent space. Given the current observation, a goal image, and candidate action sequences, the model predicts future representations and searches for actions that move the latent state toward the goal. The paper describes using the cross-entropy method for action-sequence optimization (V-JEPA 2 paper).
Meta compares this latent planner against NVIDIA Cosmos in a setup using a single RTX 4090, reporting about 16 seconds per action for V-JEPA 2-AC versus about 4 minutes per action for Cosmos in that comparison (V-JEPA 2 paper). That is a strong efficiency argument for latent planning. It is not the same as saying the system plans instantly in the robotics sense. Seconds per action still shape what kinds of control loops the architecture can support.
Physical Reasoning Benchmarks
Meta's benchmark release is part of the V-JEPA 2 story because it tries to measure physical understanding rather than surface video recognition. IntPhys 2 targets intuitive physics, MVP uses minimal video pairs to reduce shortcut solutions, and CausalVQA probes causal, hypothetical, and planning-style video questions (Meta V-JEPA 2 blog, IntPhys 2, MVP benchmark, CausalVQA).
Meta reports that human performance sits roughly in the 85% to 95% range across these physical-reasoning benchmarks, while current models still show a large gap (Meta V-JEPA 2 blog). That gap is useful. It keeps the claim honest: V-JEPA 2 improves the architecture for physical prediction, but it does not solve physical reasoning.
What Latent Models Pay For
Latent prediction buys efficiency by skipping visual details the representation does not need. It also gives up something: V-JEPA 2 is not a generative video rollout model that can render the future frame-by-frame. If your product needs controllable visual generation, a latent JEPA world model is not a drop-in replacement for a diffusion or autoregressive video generator.
The planning objective also depends on representation quality. If the latent space ignores a detail that matters for the robot, such as grasp affordance or object fragility, the planner can choose a visually plausible but physically bad action. The paper also names practical limits around camera-position sensitivity, autoregressive error accumulation, longer-horizon search, and the need for image-goal specification (V-JEPA 2 paper, V-JEPA 2 repo). This is the central failure mode of abstraction: the model can only plan over variables its representation preserves.
My Take
The elegant part of JEPA is restraint. It refuses to spend the objective on pixels when the task is understanding. That restraint makes the architecture feel closer to robotics than to media generation. A robot does not need to hallucinate a perfect future image before it acts. It needs a compact prediction of what will change if it moves.
The fragile part is evaluation. "World model" is a tempting label, and it can hide a lot of missing competence. The physical-reasoning benchmarks help because they ask whether the model understands causes, counterfactuals, and impossible events, not only whether it recognizes actions in familiar video.
Takeaways
V-JEPA 2 makes a source-backed architecture claim: prediction in latent space can produce useful video representations, and a small amount of robot action data can adapt those representations into a planner. The model's strength is understanding, prediction, and latent action search. Its limits are just as important: it does not render detailed futures, and its planner can only optimize over what the learned representation preserves. The research direction looks promising because it spends compute on physical structure instead of visual reconstruction.
References
- Meta AI, V-JEPA project page
- Yann LeCun, "A Path Towards Autonomous Machine Intelligence"
- Meta AI, "V-JEPA: The next step toward advanced machine intelligence"
- Meta AI, "Introducing the V-JEPA 2 world model and new benchmarks for physical reasoning"
- Bardes et al., "V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning"
- Assran et al., "Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture"
- DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
- facebookresearch/vjepa2 GitHub repository
- IntPhys 2
- Meta AI, MVP benchmark publication
- CausalVQA
author: Ope tag: #ai links: [[Multi-Token Prediction]] [[Spiking Neural Networks]] [[Small LLMs — Use Cases and Limits]]
